About
The Climate Difference Explorer is an interactive web application that enables users to investigate variations in temperature across two specified time ranges. This application is developed using TypeScript and utilizes WebGPU to provide efficient and performant visualizations.
Data Source
The application uses the Climate Change: Earth Surface Temperature Data dataset, sourced from Berkeley Earth. This dataset includes historical average land temperatures dating back to 1750 and extending up to 2013, and is provided in CSV format. Specifically, the tool utilizes the Global Land Temperatures By City data, which includes monthly temperature averages for various cities, as well as geographical coordinates (latitude and longitude) to enable data aggregation and visualization.
Data Preprocessing
The Climate Difference Explorer uses a custom offline data processing pipeline to convert the raw CSV data into a format that is more suitable for the visualization. Furthermore, the pipeline also performs data compression to reduce the size of the data file, which is served to the client. The pipeline is implemented in Python and the resulting file is served to the client together with the application.
The preprocessing pipeline performs the following steps:
Step 1: Data Interpolation
The first step in the pipeline is to interpolate the data to fill in missing average temperature values via linear regression. The interpolation is performed on a per-city and per-month basis, and is done by first computing a linear regression model utilizing existing values, and then using the model to predict the missing temperature values.
Step 2: Data Compression
The second step in the pipeline is to compress the data with the following steps:
- Getting rid of unnecessary data (like city names and countries)
- Creation of a lookuptable for the different positions inside the dataset
- Saving dates as month difference to the first date in the database
- Converting numbers into the smallest binary representation possible
- Discretizing temperature values.
The resulting data is then stored in a binary LZMA (Lempel-Ziv-Markov chain algorithm) compressed format, which is more compact than the original CSV format. This is done to reduce the size of the data file, which is served to the client. By the just described steps we achieved an overall compression rate of 98,61% (for 2 byte discretization) or 99,41% (for 1 byte discretization)
Visualization
A custom visualization is implemented using TypeScript and WebGPU to provide efficient and performant rendering. The code is transpiled to JavaScript and executed in the client browser.
The steps of the visualization pipeline are as follows:
Step 1: Data Loading
In the first step, the compressed data file is loaded into memory and decompressed in the client browser by reversing the process described in the Data Preprocessing section. The decompressed data is then transferred to the GPU utilizing WebGPU buffer.
Step 2: Grid Creation and Data Aggregation
The second step involves creating a hexagonal grid and aggregat the data into its cells. This is done by using a WebGPU compute shader, which sums the temperature values within each cell for both time ranges to be compared, and then calculates the average temperature for each cell by dividing the sums by the number of summed data points. A second compute shader then finds the minimum and maximum values for the entire grid, which are used to determine the color shading of the grid cells.
Step 3: Data Rendering
In the final step, a world map is rendered on the canvas. The hexagonal grid cells are then overlaid on the map and shaded according to the calculated temperature difference values. The resulting visualization provides a representation of the data that allows to quickly see temperature differences in various areas around the world.
User Interface
Since the WebGPU standard is still in its early stages of development, the application can currently only be used on the latest version of Google Chrome Canary.
After opening the application in the browser, the data is loaded and unpacked.
Once finished, the visualization is rendered on the canvas. The application is divided into three sections:
- The visualization, which encompasses the entire screen and includes a legend, displays the selected data on a world map.
- The configuration window allows users to select the year ranges to compare and adjust various display options.
- The information window provides an overview of the currently displayed data, technical information, and a brief help guide.
Visualization
The visualization groups the underlying data into hexagonal bins, each of which represents a specific geographic area. Data points within each bin are aggregated into a single value, which is then represented by the color of the hexagon. The color of the hexagon indicates the change in the average temperature by comparing the selected year ranges. The legend, which provides context for the colors used in the hexagons, is displayed at the bottom of the visualization. If a bin has no data points, it will appear transparent by default.
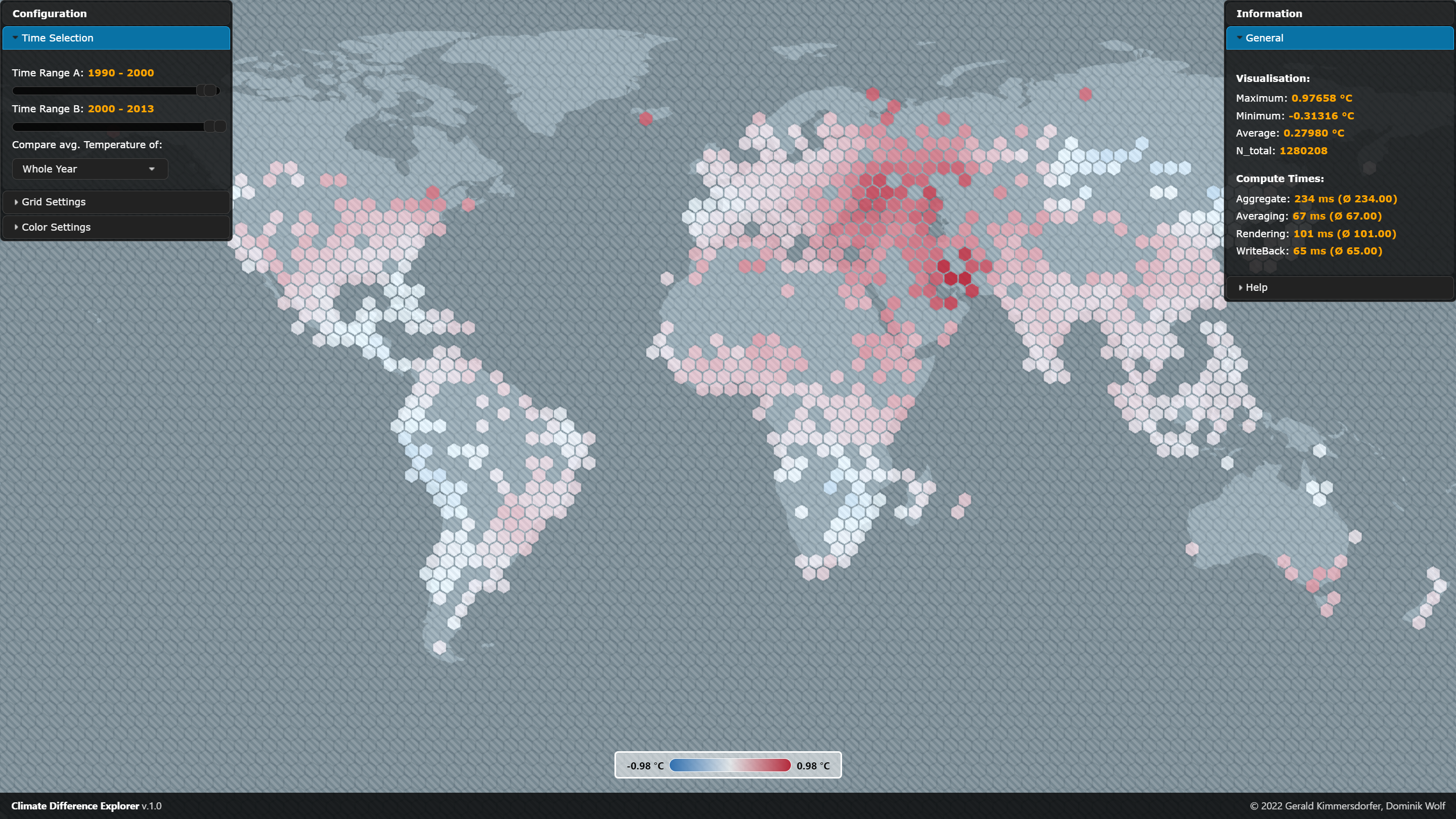
When the mouse cursor is placed over a hexagon, additional information about the bin is displayed as a tooltip. This information includes, among others, the grid coordinates of the bin and the exact value of the aggregated data points within the bin.

Configuration Window
The configuration window is organized into three sections:
- The time selection section allows to select the date ranges for comparison.
- The grid settings section provides options for configuring the hexagonal grid in the visualization.
- The color settings section allows to adjust the colors used in the visualization.
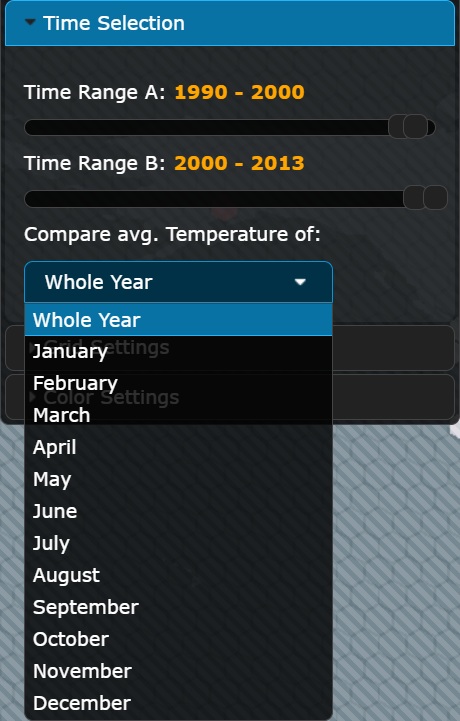
Time Selection
The time selection section enables users to select two year ranges for comparison. Users can select the start and end years for Time Range A and Time Range B using sliders. Additionally, a drop-down menu allows users to choose whether to compare the average temperature values for the entire year or for a specific month.
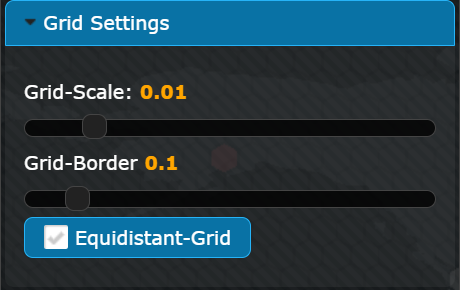
Grid Settings
The grid settings section of the configuration window allows to customize the hexagonal grid displayed in the visualization. The section includes sliders for adjusting the Grid Scale, which refers to the size of the individual hexagons of the grid, and Grid Border, which refers to the thickness of the border around each hexagon. Additionally, users can toggle on or off the equidistant grid option, which ensures that all sides of the hexagons have the same length. When the option is deselected, the hexagons will be distorted to match the aspect ratio of the underlying world map.
The Grid Scale and Grid Border settings affect the coverage of the hexagons on the world map, so when these settings are adjusted, the aggregation of the data points will be recalculated.
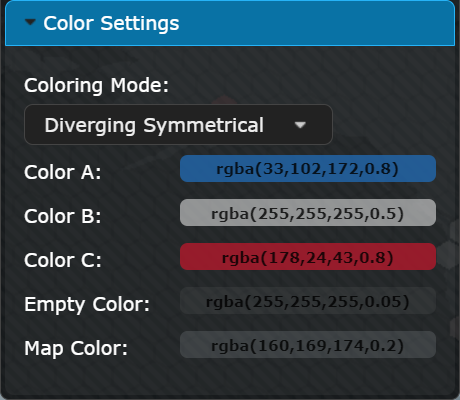
Color Settings
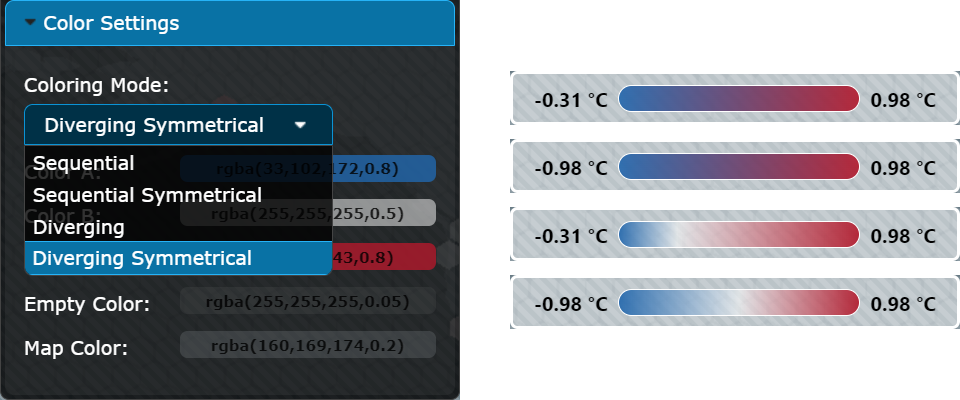
The color settings section allows users to switch between a sequential or a diverging color map using a drop-down menu. Sequential color maps use a progression of colors between two colors, while diverging color maps use two different colors that progress through a neutral color in the middle. Users can select the start and end colors of the gradient for both types of color maps using a color picker. Additionally, when using a diverging color map, users can also select the neutral color in the middle. The section also offers the option to use a symmetric variant for both color maps, which shows the same range of values at both ends of the scale. In addition, this section provides an option to customize the colors of the empty hexagons and the world map background.
Information Window
The information window is organized into two sections:
- The general section that displays information about the data currently being visualized.
- The help section that offers a brief introduction to the application and its features.
General
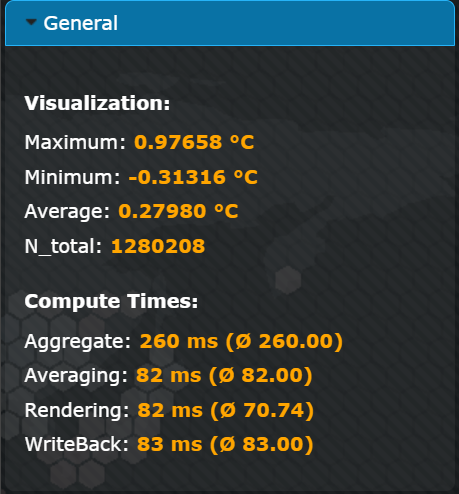
This section displays statistical values about the visualized data, which include:
- Visualization
- Maximum, Minimum, and Average: The highest, lowest, and average value of the data points within the entire grid.
- N_total: The total number of data points currently aggregated.
- Compute Times
- Aggregate and Averaging: Time taken by the compute shader to process the data.
- Rendering: Time taken for rendering the map and grid.
- WriteBack: Time taken for writing the aggregated data back to the main memory for client access.
Help
This section offers a brief overview of the application, including its features, data sources, and useful keyboard shortcuts.

Developing Notes
Getting the source code
You can get the source code of the Climate Difference Explorer from our github-page.
git clone https://github.com/GeraldKimmersdorfer/rtvis22-cde.gitSetting up developing environment
The application is developed using the npm-Manager, so
before you can start coding you need to install Node.js. To download the required
packages execute the following command:
npm install That should be it. You can build the application by executing:
npm run devTo generate a production build you may use npm run prod.
If you wanna have hot-reload of your typescript and shader-files aswell
as the webpack developing server you want to run:
npm run serveNote on working with Visual Studio Code
I advice to use the WGSL-plugin for Code-Highlighting in Shader-Files. If you, for whatever reason don’t want to work with the webpack server you can use the Live Server-plugin.